One of the most common questions I get from video customers is, “What do 10-bit 4:2:2 and 8-bit 4:2:0 actually mean?” The explanation can get pretty technical, so it’s easy to default to the opinion that higher numbers equal better footage. That’s true in a sense, but following that logic leads to another common question: “I absolutely must shoot Raw, but I have a limited budget and no crew. What do I do?” See, more information leads to higher data rates, which result in higher media costs, which lead to higher backup storage costs, which lead to higher post-production costs, all of which may be unnecessary depending on where your footage is going to end up. It’s like filling a water balloon with a fire hose. More isn’t always better. That’s why it’s important to learn the technical differences between these methods of video compression.

Rods and Cones
To understand how compression will affect your final product, it’s helpful to know a little bit about how the human eye processes color. Remember the phrase “rods and cones” from middle school biology? If it slipped your mind or got repressed with the rest of your middle school memories, here’s a quick refresher: we detect color with two types of photoreceptors: rods, and cones. There’s about a century’s worth of detailed research about this and multiple theories about how the two interact, but for our purposes, all you need to know is that the cones detect color, while the rods only detect luminance. If you, god forbid, wake up tomorrow morning with no cones you’ll still be able to see, but everything will be black and white. With no rods, you’ll have a much harder time. Our brain creates an image by combining color information from the cones with luminance information from the rods to produce shades. Since we have around 20 times as many rods as we do cones, we’re far more sensitive to changes in luminance than we are to changes in color.
Helpful analogy time. Imagine a painter, a French one in a park. He’s working on a portrait of the Eiffel Tower, baguette and red wine by his side. He’s probably wearing a beret. What is he holding in his left hand? A bag filled with billions of vials containing every possible color in the visible spectrum? No, it’s a painter’s palette. If he needs a slightly lighter shade of green, he simply mixes the hue he’s got with some white paint. This way he can create many different shades of green with the same hue. Our vision works in a similar way. It’s estimated that the human eye can see about 10 million distinct hues (detected by 6 to 7 million cones). Each of those hues, though, also has a luminance value (detected by 120 million rods). Combine the two, and the number of possible colors is nearly infinite.
Since camera sensors are designed to replicate the biological function of the human eye, they process color in a remarkably similar way. Just as we have rods and cones to detect color and luminance, video cameras detect luma and chroma information. For digital video to be recorded and distributed efficiently, file sizes and data rates have to be manageable, which means some of this luma and chroma information has to be ignored. Compression, at a basic level, is just a means of deciding what information to keep and what information to throw out. One of the earliest and most common methods of video compression is called chroma subsampling. 12-bit 4:4:4, 10-bit 4:2:2, 8-bit 4:2:0, etc., are just shorthand representations of the type of chroma subsampling that your camera or recorder is performing.
Bit by Bit
The first thing to know about the 10-bit 4:2:2 or 8-bit 4:2:0 designation is that it’s giving you two different pieces of information. The first part, “10-bit,” refers to the bit depth of the image, sometimes referred to as color depth or BPP (bits per pixel). While this has an effect on chroma too, it’s easier to understand if you think of it first as a descriptor of luma. If you think of luma as a range from absolute black to pure white, bit depth is the number of gray shades between those two values represented as a power of two. So, switching from middle school science class to middle school math class, 28=256. A monochrome 8-bit image would be made up of 256 different shades of gray. Color sensors determine chroma by sampling three different channels, red, green, and blue. An 8-bit color image has 256 shade values in each of those channels. So, the number of possible colors in an 8-bit image is 256 times 256 times 256, or about 16.7 million. 10-bit will give you 1024 shade values, 12-bit 4096, and so on.
The video engineers who developed chroma subsampling realized that, in the same way the human eye prioritizes luminance over color, they could ignore a lot of the sensor’s chroma information to reduce data rates. This is where the “4:4:4, 4:2:2, or 4:2:0” part comes in. To have a visible image, every pixel needs to have its own luma data. That is, every pixel needs to know how bright to be. However, since we process color as a combination of luminance and chrominance anyway, not every pixel has to have a chroma value. By throwing out some of the extraneous chroma information, you can significantly reduce the file size of an image without a noticeable loss in image quality. “4:4:4, 4:2:2, and 4:2:0” are just numerical representations showing how much chroma data is being ignored.
These are three-part ratios commonly expressed as J:a:b, where “J,” (4 in most cases) is the number of horizontal pixels being referenced. The following two digits, 4:4, 2:2, or 2:0, represent the number of pixels in two rows that will receive chroma samples. It’s a little confusing until you look at it represented graphically, so here’s a picture:
So, to start, what we’re looking at are two rows of four pixels, row a and row b. Every one of these pixels will receive a luma value, so I’ll go ahead and add an L to each block.
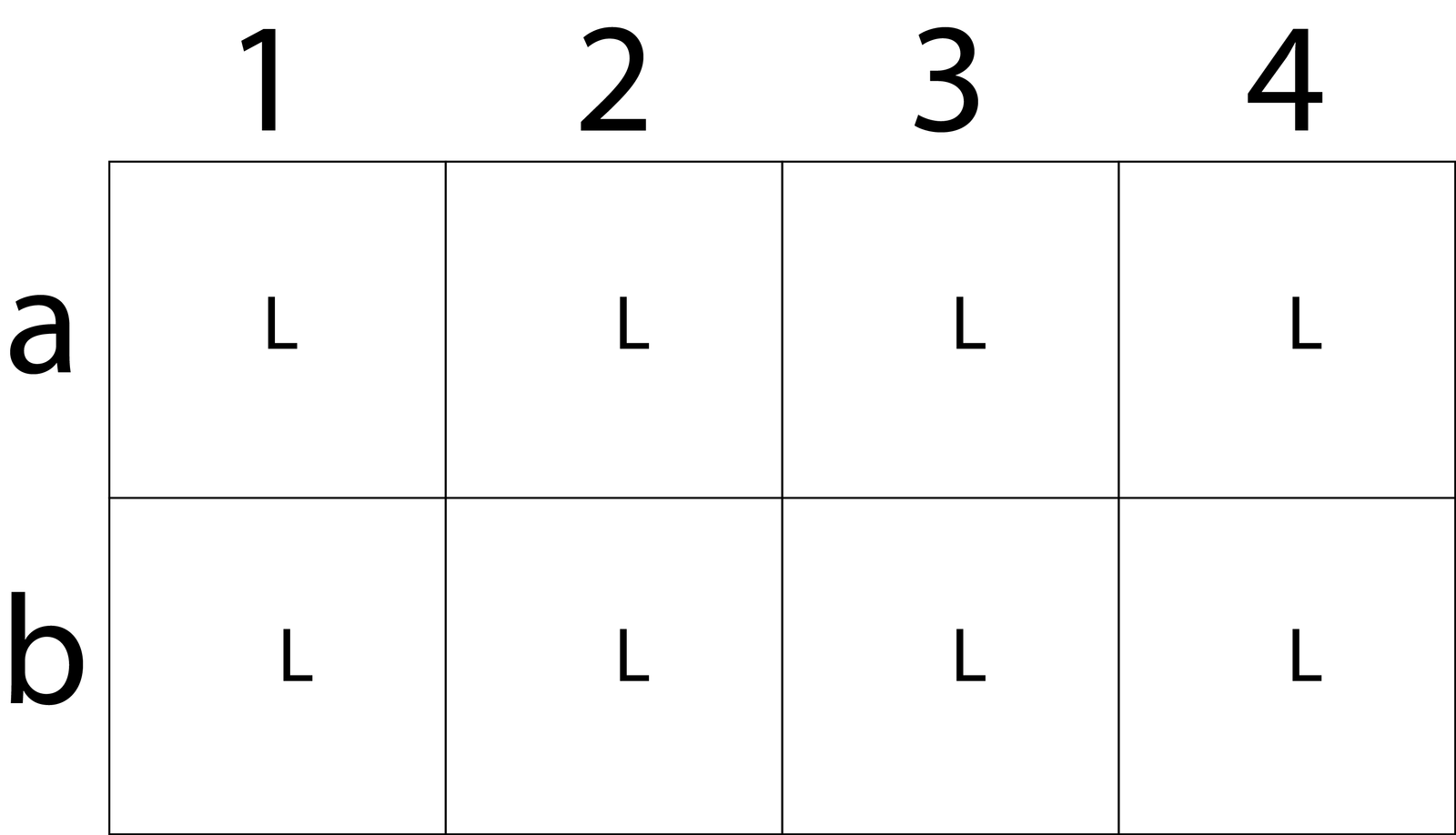
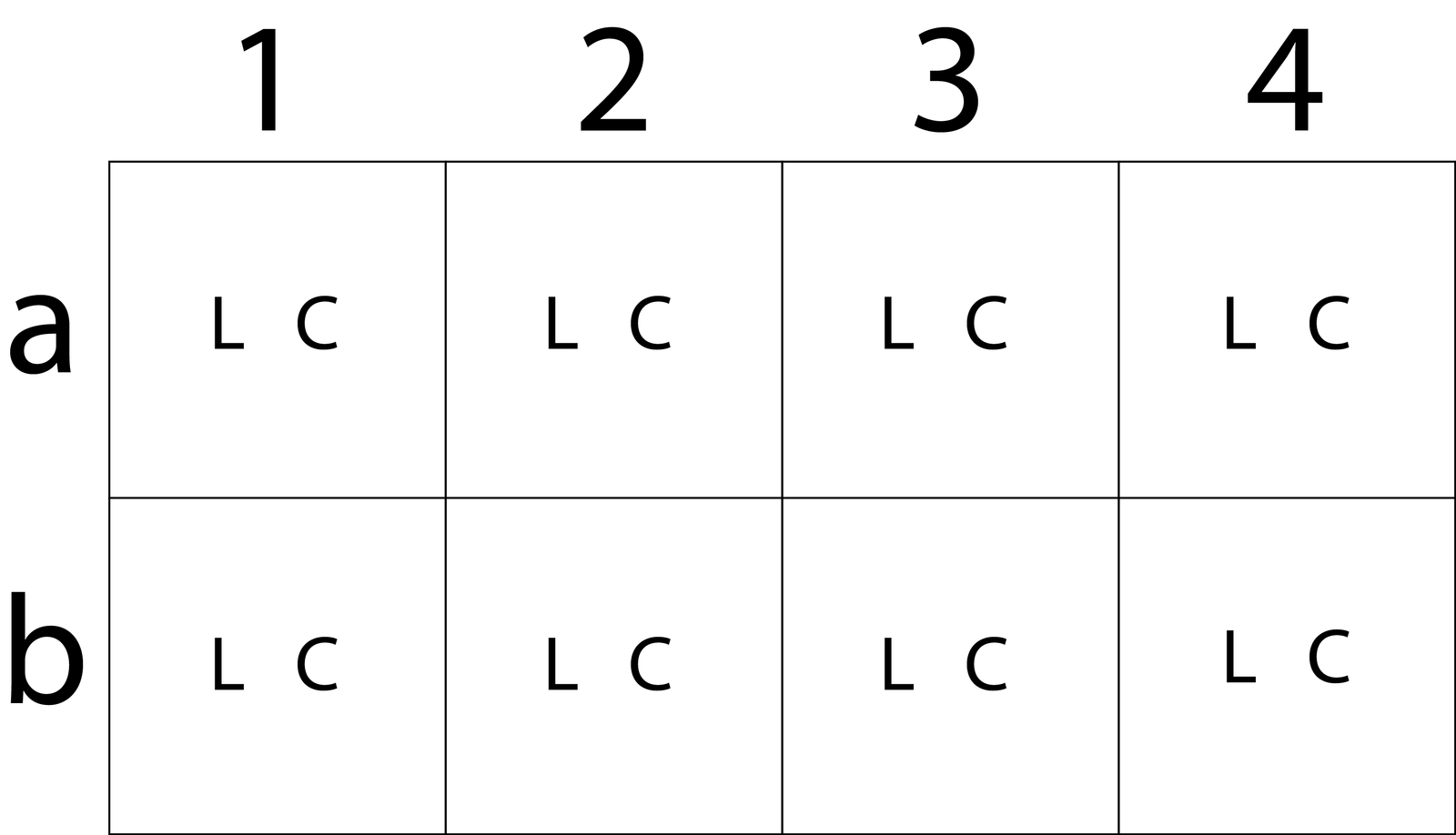
Luma being a measure of brightness, this just tells us that every pixel knows how bright it needs to be. This is all the information we’d need for a monochrome image. Next, the a and b numbers in the ratio indicate how many pixels get chroma information. We’ll start with 4:4:4, which is showing that no chroma subsampling is happening. Every pixel in a 4×2 group gets its own luma and chroma data. Represented visually, it’d look like this:
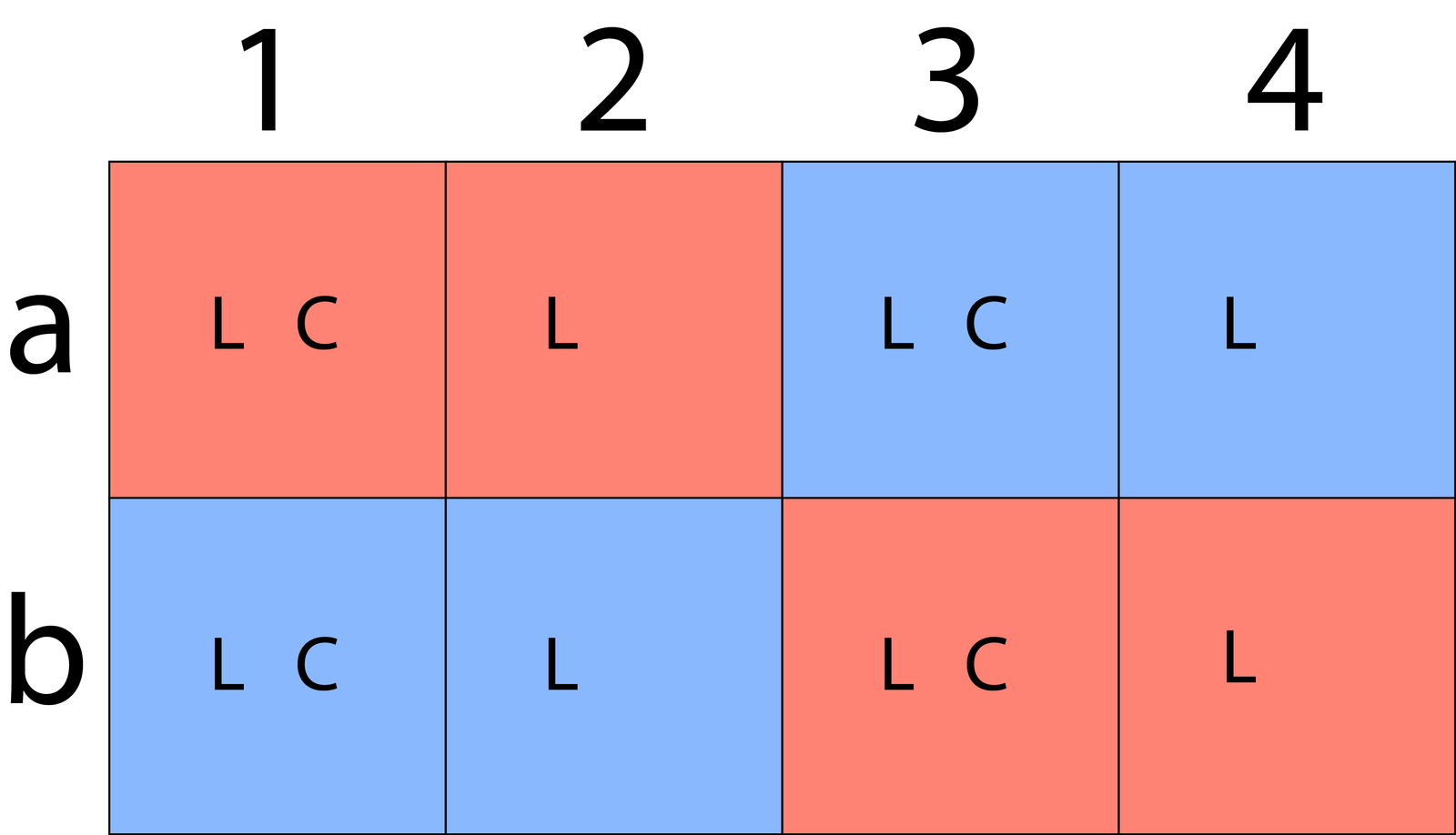
I’ve added color to indicate which pixels are sharing chroma data. This isn’t to say that pixels sharing chroma data will be the same color, just the same shade. Since they still have unique luma data, their brightness values will still vary. 4:2:0 chroma subsampling looks like this:
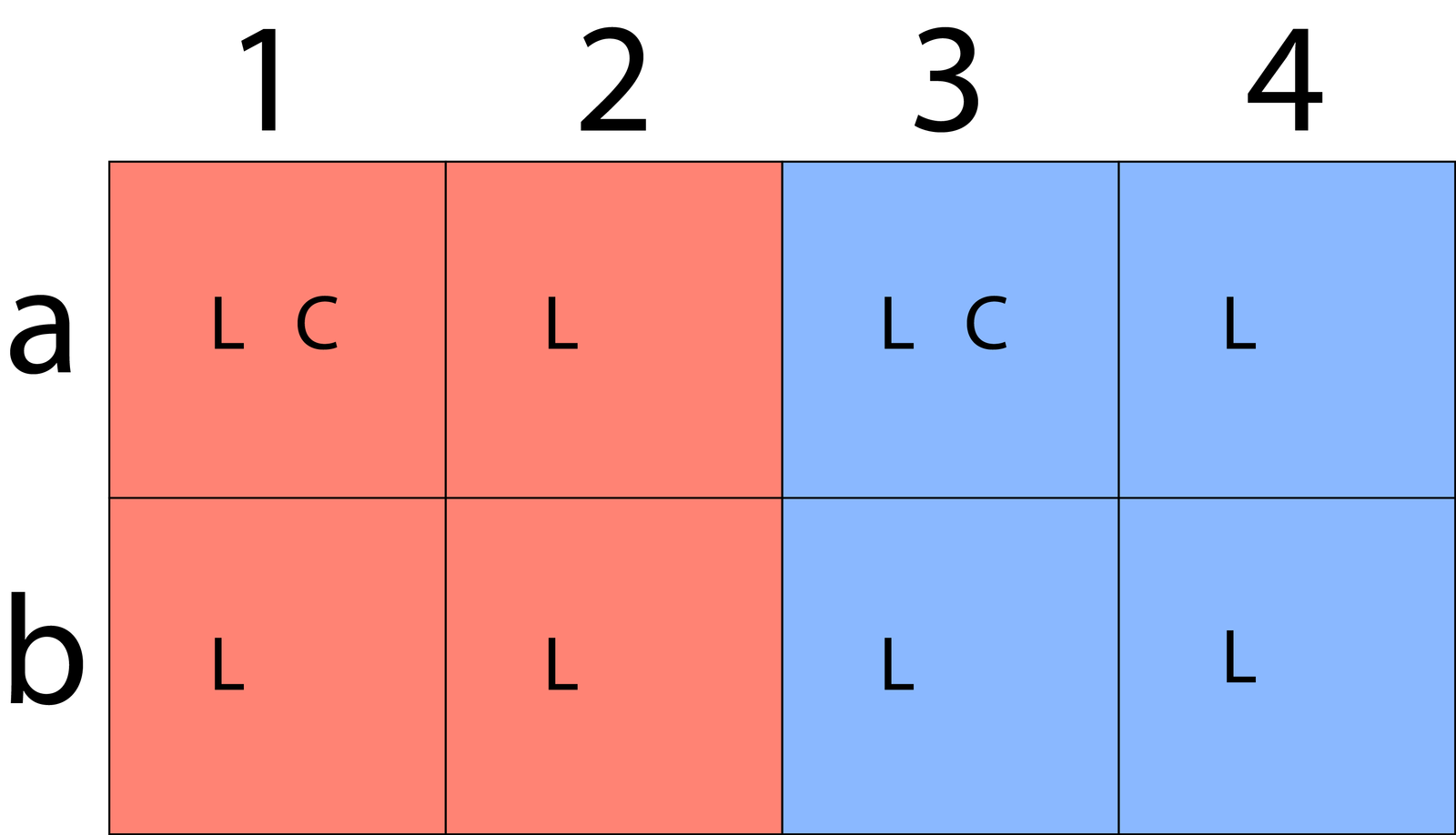
Again, every pixel still has unique luma data, but now only 2 pixels on row a get chroma data. Row b pixels are sharing their chroma data with row a, so every 2×2 block of pixels in the image is sharing a single piece of chroma data.
“I Don’t Want to Read These Charts. Please Summarize This Information”
Seen this way, it can appear that you’re throwing away an awful lot of information when capturing 4:2:2 or 4:2:0, but the real-world effect ends up being pretty negligible. In a 4×2 pixel grid, you can certainly see a difference, but keep in mind that, for video at least, these images are usually 1920×1080 pixels or larger. Subtle differences in color from pixel to pixel are almost impossible to spot, so the lower data rate is worth it. In fact, most video you see day-to-day is 8-bit 4:2:0. That includes nearly all web video, streaming services, broadcast television, DVD, and even Blu-Ray. Depending on how old your neighborhood movie theater is, you might even be seeing 4:2:0 projection there. Long story short, it’s nearly impossible to visually tell an 8-bit 4:2:0 image from a 10-bit 4:2:2 one. Even if the human eye could detect a difference, almost no one at a consumer level can distribute a 10-bit 4:2:2 image anyway. Given those facts, why would you ever choose to waste storage space on 4:4:4 or 4:2:2? Color correction. If you’re adjusting color in post, the more chroma information, the better.
In making recommendations to customers, my rule of thumb is this: If you’re shooting green screen footage, doing VFX work, or are paying a professional colorist, then you might need RAW or 4:4:4. If you’re doing your own color correction, then 10-bit 4:2:2 is probably fine (10-bit 4:2:2 is usually what I stick to, for instance). If you’re editing the footage straight out of the camera and not doing any color correction, then 8-bit 4:2:0 is usually plenty, since that’s all most people will ever see anyway. Camera-wise, it’s tough to recommend anything without knowing specific details about what you’re trying to do, but I can wholeheartedly endorse the Odyssey 7Q+ for any external recording. It’s the most reliable recorder we carry and will capture a wide variety of color depths from any number of cameras. Your needs will likely vary from project to project, so if you have any questions, feel free to give us a call, and we’ll happily talk you through it all.
Finally, I consulted a lot of different articles when researching this post. By far the clearest and most in-depth explanation of these concepts I could find was on wolfcrow.com. If you’d like a more detailed explanation than I can go into here, check out their site.

11 Comments
Ben Nieves ·
A good way to see the difference between 8 bit and 10 bit footage (assuming you have access to both types) is to simply load the footage into an NLE with color correction capabilities and try some corrections. You will soon see that the 8 bit footage cannot be graded as much without producing color banding or unusual color shifts. That’s why I like 10 bit footage even though it’s a storage hog.
Carleton Foxx ·
I’ve had the same experience. Shooting in 8-bit requires a much more disciplined and conservative approach with regard to exposure and white balance because you can’t spin the color correction wheels around like you can with higher-depth footage.
If you shoot in 8bit be sure to rent some of LensRentals many fine small LEDs to fill in shadows, refine midtones and add highlights, you’ll thank yourself later.
Samuel H ·
That depends a lot on the codec. XAVC-S is VERY good. This video does exactly what you’re describing, and concludes 8-bit can be good enough in most situations:
https://www.youtube.com/watch?v=AekKwgvS5K0
Kristian Wannebo ·
Typo (?)
Under the graphic illustrating 4:2:2 :
“Since they still have unique chroma data, ..”
Shouldn’t this be “luma data”?
The LINK
to wolfcrow.com
at the end seems to be broken.
Ryan Hill ·
Thanks! You’re right on both counts, and I’ll work on getting this corrected.
Nqina Dlamini ·
Thank you for your explanation. I enjoyed it and it was informative.
Samuel H ·
Then again, in practice, if the codec is good enough (as XAVC-S is), H.264 8-bit 4:2:0 can be almost as good as 10-bit ProRes:
https://www.youtube.com/watch?v=AekKwgvS5K0
Ed Bambrick ·
That Kenny Roger’s sign screwed up my rods and cones. https://www.youtube.com/watch?v=mwoJC7fowsk
Arthur Meursault ·
That Kenny Roger's sign screwed up my rods and cones. https://www.youtube.com/wat...
zrav ·
I routinely see artifacts originating from 4:2:0 subsampling when you have red text or objects on dark/black background. IMO it is time the mainstream moved to 4:2:2.
10 bit might not be necessary for your standard rec.709 media, but with larger gamuts and HDR it should be standard even for consumer delivery formats as otherwise the banding becomes visible in enough situations.
Dmitry Anisimov ·
The rod/cone cells mention here is a red herring. Rods participate only in low light and enter saturation in good light. Large number of rods is because rods are binary detectors and one neuron accumulates signal from multiple rods.