I’ve written before about how important interview transcription is to a documentary editing workflow, and, as an occasional documentary editor, I’ve tried countless different solutions in search of an option that works for me. In my film school days, I’d just open up an interview in Final Cut, play it back in real-time, and type the whole thing into a Microsoft Word document, adding timecode and speaker notations manually as I went. As a person who was deprived of the opportunity to take typing in high school, this took absolutely forever. At my best, I could write out an interview in about 5-7 minutes per minute of footage. A half-hour interview could take three hours to transcribe before I could even start editing, longer if there were multiple speakers involved. That just wasn’t a sustainable workflow, even after I stole one of those foot-controlled transcription pedal things from my part-time legal assistant job.
Since then I’ve tried paid transcription services (accurate but expensive), before moving on to early versions of the various speech to text software that makes up the majority of the market today. I even went through a brief period where I tried hacking a usable setup out of software that wasn’t really designed for it. This is a digression, but I think it’s important to understand the kinds of workarounds that were necessary less than ten years ago. After being hired to edit a long-term documentary project with dozens of hours of recorded interviews and no budget for paid transcripts, I thought I’d try to save myself some late nights by using Dragon NaturallySpeaking, a piece of software designed to turn speech to text. At the time, though, it was designed for dictation, not transcription, meaning it would only recognize one person’s voice (through an included headset) and had to be trained by the user reading several pre-written scripts into the software. In short, I couldn’t just feed it audio files and have it give me text. I actually had to speak into it for it to work. So, I’d play the interviews to myself through headphones, then repeat every word myself out loud into the microphone. This actually worked pretty well except that it severely weirded out my roommates. Imagine living with someone who spends long stretches of each day robotically repeating out of context interviews, including punctuation, into a computer in the middle of the living room. By popular demand, the workflow was abandoned.
All that to say, this is a problem people have been trying to solve for a long time, and it finally feels like we’re getting to the point where software can take over most of the work. There are now several options available for automated speech-to-text both as first-party integrations from companies such as Adobe and from third-party standalone and plug-ins from companies like Descript. These all work varying degrees of well. Any application will need some correcting, but even the least accurate solutions save a lot of time compared to writing everything out manually. So, when Davinci Resolve (my current favorite NLE) added built-in speech recognition and transcription in their recent 18.5 beta update, I was super excited to try it out. Hopefully, this means no more cobbled-together workflows involving plug-ins and third parties. If it works, it’s always easier for everything to be built directly into the app.
So, to start with the headline three paragraphs in, it DOES work. It works extremely well. In fact, while I haven’t tried every single solution on the market, I’d say Resolve’s built-in speech-to-text is the best I’ve used so far, including paid options. Before I get into too much detail, though, let’s talk about the media I used. While I experimented with a handful of clips from various sources and in varying degrees of quality, most of my testing for this article was based on an event I recorded about a year ago. This was a moderated interview/conversation between two subjects and a host, including a Q&A portion toward the end where everyone took questions from the audience. These interview subjects, I should say, are Jim Obergefell and Al Gerhardstein who have done and continue to do extremely important work in civil and LGTBQ+ rights. They’re best known as the lead plaintiff and lead counselor from the Supreme Court case Obergefell v. Hodges, which legalized same-sex marriage in the United States. What I’m saying is, they’re a much bigger deal than the blog article I’m offhandedly mentioning them in.
Anyway, I chose this not because it’s my all-time best cinematography work (it’s not), but because it presents a situation that could be challenging for software-based transcription. The nearly two-hour-long single clip features several different speakers and audio quality that range from fine to bad. The two lav mic’d interview subjects sound pretty good, but the moderator with a handheld mic has some echo and feedback. Then some of the audience aren’t mic’d at all, coming in only through the handheld mic on the stage. Again, I’m admitting this isn’t my best work. But it did make a good test case. And I’m happy to say that Resolve mostly passed that test.
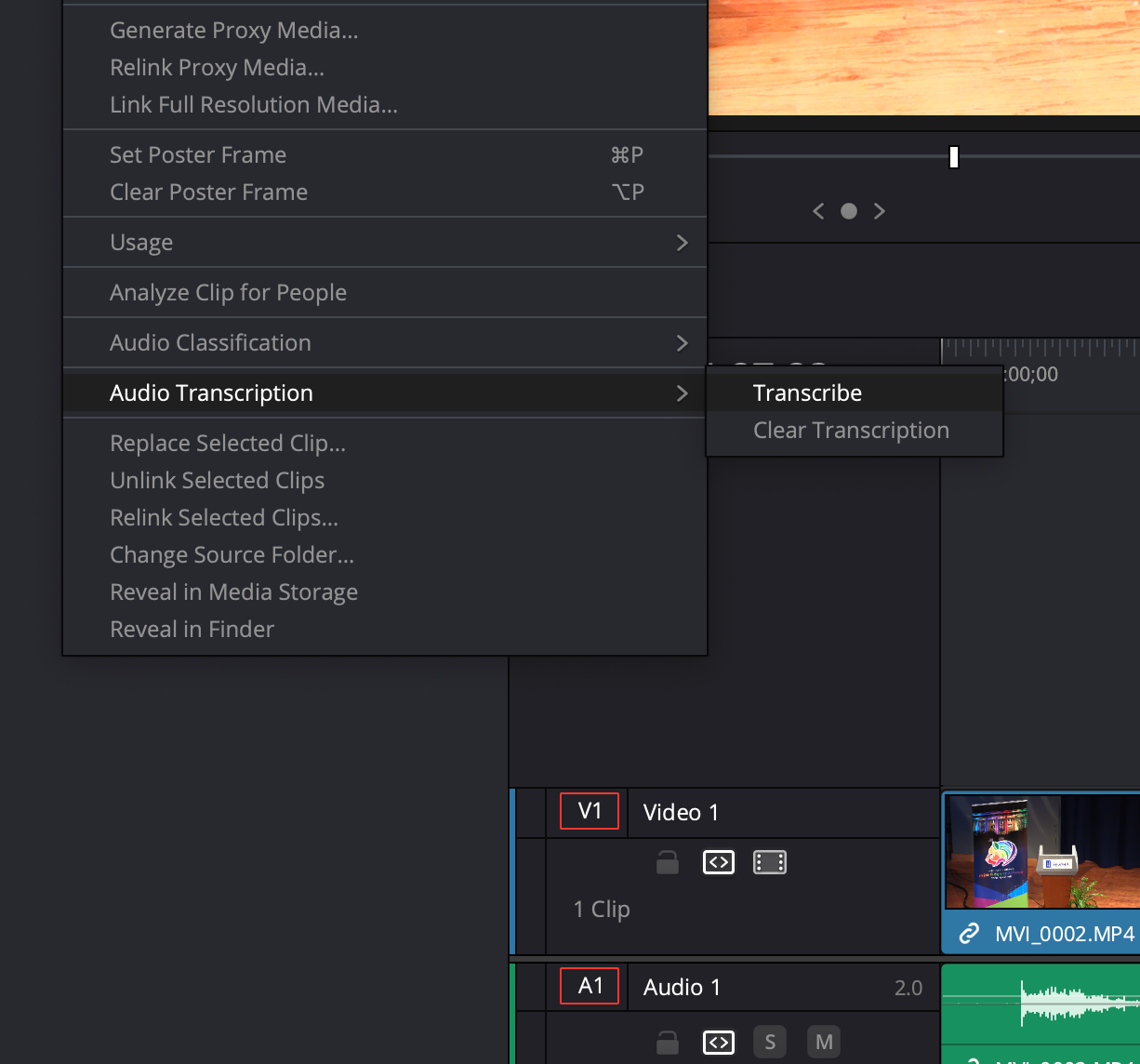
The process of transcribing audio in Davinci Resolve is a pretty simple one. In either the edit or cut panels, all you need to do is right-click any clip, then select “Audio Transcription>Transcribe”. The processing time required will vary based on your computer, the length of the clip, and the quality of the audio, but I wouldn’t expect a significant wait regardless of any of these variables. As an example, on my M1 Pro-equipped Macbook Pro, transcribing this 102-minute clip took about 7 minutes, just enough time for me to take a short walk around my block. It’s a perfect excuse for a break.
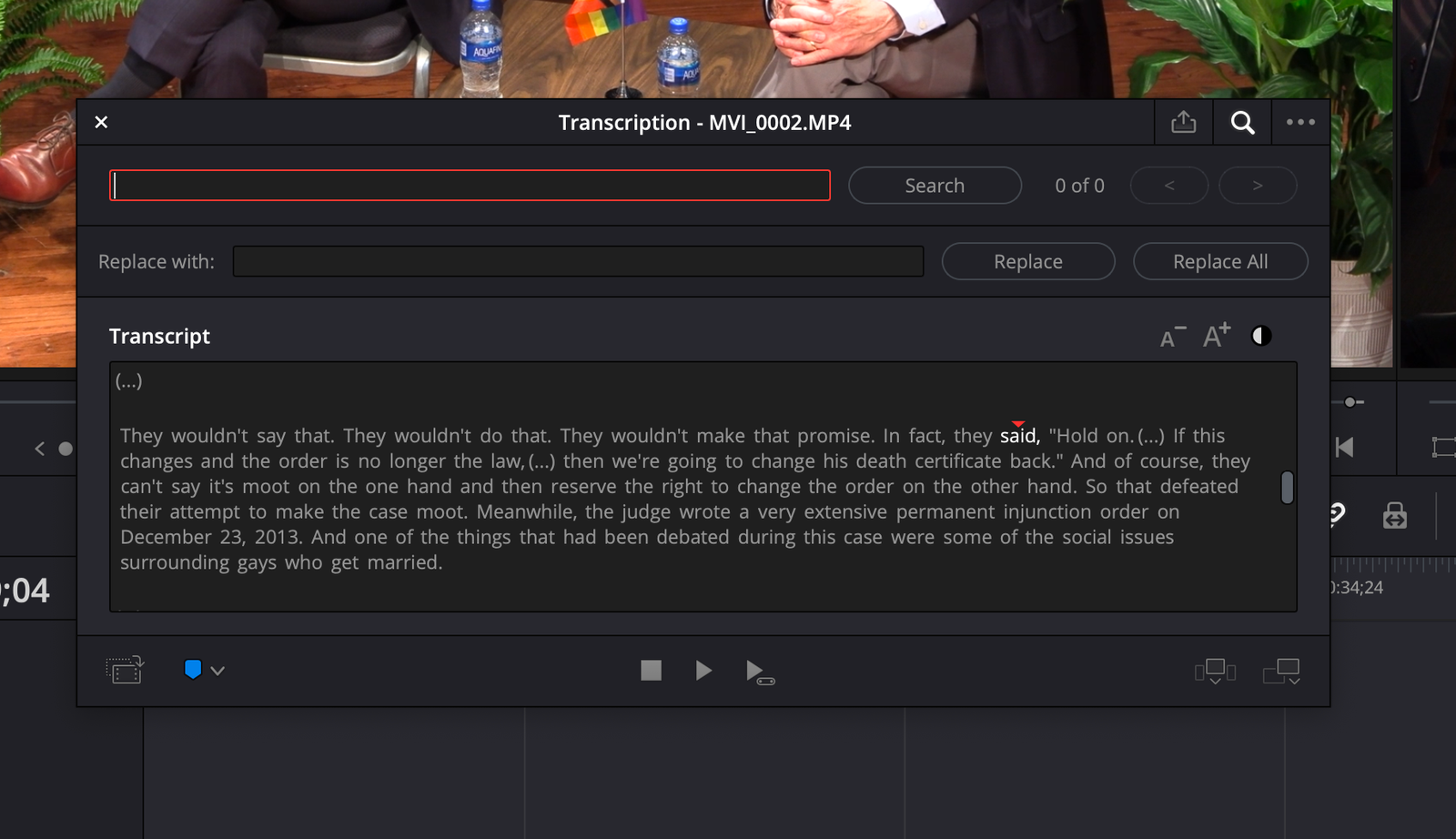
After your little break, Resolve delivers you a remarkably good transcript! I was especially impressed by the accuracy of the punctuation here. This is something that, in my experience, has always been a struggle with software transcription. It’s one thing to be able to translate speech to text, quite another to be able to understand the tone and add commas and periods where appropriate. I was amazed to find that Resolve could even recognize the need for quotation marks when someone is quoting another person. That’s the kind of thing I’ve become accustomed to having to go in and fix myself. While this stuff isn’t absolutely essential if you’re just using transcripts for your own reference, the added polish certainly helps you’re working with a client.
I also noticed that Resolve does a fantastic job of skipping over “Um”s “Ah”s and false starts, those kinds of thinking words that can just crowd up a transcript. And, in a very nice touch, it will also recognize and note applause. The software does make the occasional mistake, especially with technical language and names, which is inevitable. Once you catch those, though, fixing them is just a matter of finding and replacing any misspellings. You can also edit individual sections of the transcript or delete parts entirely, including silence, which is represented by ellipses. The user interface for all of this, while a little utilitarian, is clear and relatively easily navigated. It’s at least a great start for a beta.
Resolve presents a ton of helpful options when it comes time to edit using a transcript. In addition to being able to search for particular words or phrases, clicking at any point in the transcript automatically brings the playhead to that point in the viewer window. You can add markers at certain points directly from the transcript window, create sub-clips from selections, and even insert or append selected text as clips directly to your timeline. With all of these features used in conjunction, it’s relatively easy to create a rough cut of an interview using ONLY text. Working this way obviously saves a ton of time, but there’s a less obvious advantage. Everyone has a different approach to editing, but, at least for me, working with interviews as text helps my process by putting me in a different frame of mind. This is borderline old-person behavior, but, for projects with a lot of talking heads, I actually like to print out all the transcripts, highlight picks by hand, and then put a text script together to work from. It’s just easier for me to think about the best way to get information across to the audience if I first think of it as a writing project before I get into actual video editing. That’s not true of everyone, of course, but if transcripts are an important part of your workflow in any way, Blackmagic has added a hugely important feature here, and they’ve integrated it remarkably well so far.
Having these transcripts at hand also obviously makes it far easier to generate subtitles. Simply navigating up to the top menu and selecting “Create Subtitles from Audio” brings up a dialog window that includes several options, including Netflix standards, which are apparently pretty specific.
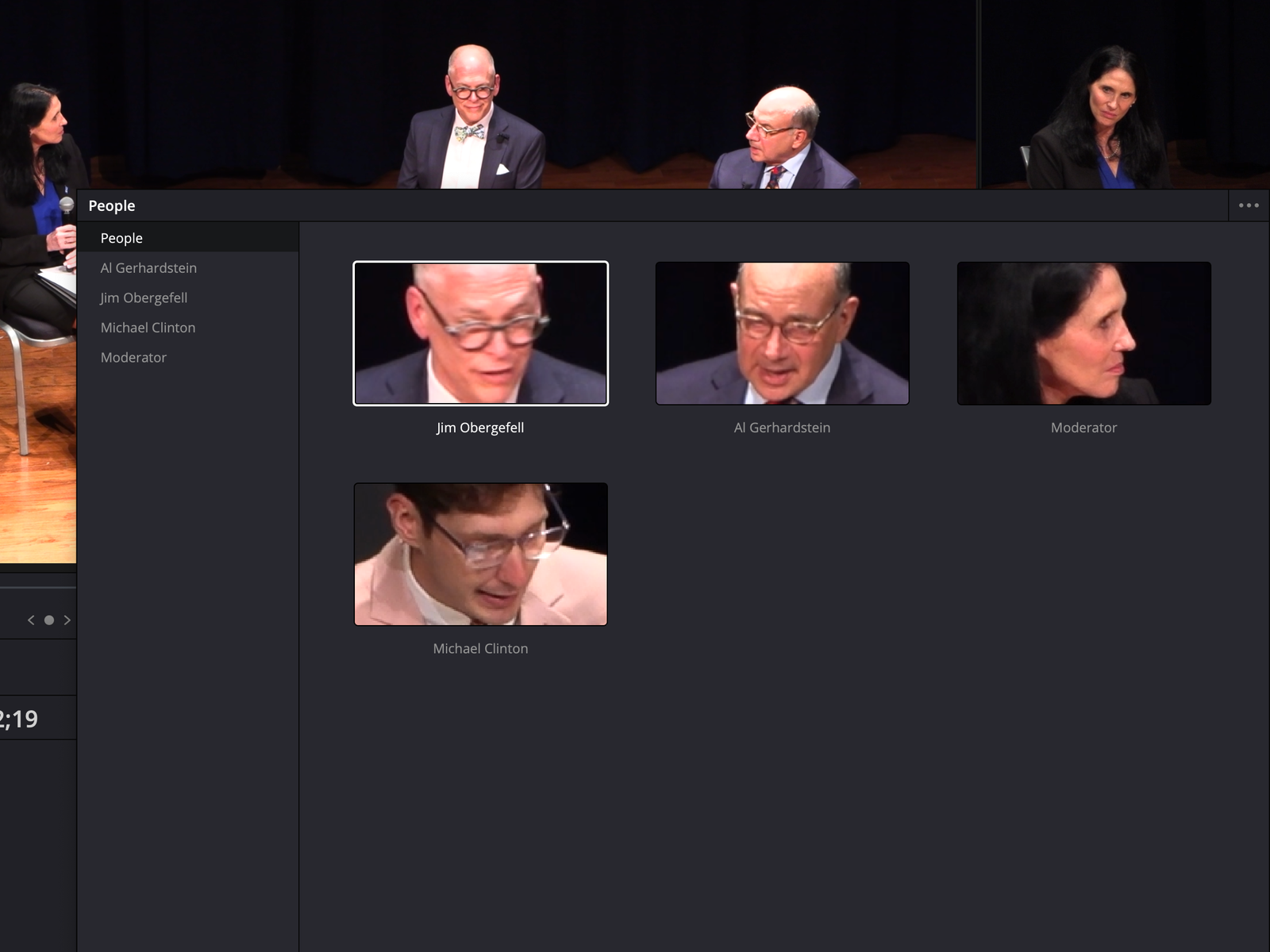
However, as happy as I am with where things are in the beta, there’s definitely room for improvement. Most importantly, I’d love to see better support for multiple speakers. As far as I can tell, Resolve doesn’t seem to be able to recognize or note in the transcript when one person stops talking and another begins. This is pretty essential information to have, and it’s time-consuming to add yourself, especially in situations with more than a couple of people on screen at a time. I’m especially surprised at this omission because Resolve does have an effective face recognition feature. If I’m able to scan multiple clips for faces, then identify those people and have Resolve pick out instances where they appear, it doesn’t seem like a huge additional step to then have Resolve be able to tell me who is speaking, at least if they’re on-screen. It wouldn’t take recognizing a speech pattern, just connecting the facial recognition technology you already have to the new transcription feature.
I’d also like to see more options at export. While Resolve will allow you to export a transcript, the only options right now are plain text files without a timecode. When working with clients, or even for some archiving workflows, timecode support could be essential. While I’m sure there’s a way I could work around this by embedding the transcript as subtitles and then using exporting a subtitle track, those are a lot of steps to go through for something that should be relatively simple. Just give me a checkbox at export to include the time code. While we’re at it, once you’ve added the ability to recognize different speakers, note those in the exports as well. Both of these are pretty small changes that I think could make the user experience that much better.
This is a beta, though, to be fair. I’m sure Blackmagic is hard at work taking notes and making improvements for the next version. For now, this is one in a long list of free updates to an NLE that’s already one of the best deals around. Transcription being an indispensable tool in my editing workflow, I’m happy to see it finally get added to Resolve natively, and I’m looking forward to seeing how it improves in the future.

4 Comments
Roger ·
This looks really great and Resolve seems to be poised for future speaker detection.
As an alternate workflow I've gotten used to SubtitleEdit with OpenAI Whisper "Faster Whisper" integration (though the CPU-only CPP and less accurate but crazy fast Const-ME implementations also work well). All processing is done on your computer but if you have a 20XX+ NVIDIA with CUDA this can go very quickly and it's 100% free. The large model does well with strange proper nouns as well (foreign place names, etc.)
https://www.nikse.dk/subtit...
https://github.com/Softcata...
Then import the SRT file and work from there.
Flori Pilsl ·
I can still remember the 80+mph version of transcription: me driving like hell, Reporter with camera on lap, writing in’s and outs to the best bits, three words in, last three and the timecode start-ish. Always worrying about the heads crashing
I am looking forward to this becoming very robust, I have a lot of stored interviews in multiple languages, would love to create an archive of all. The cards/tapes become my memory bank
Do you have to be online? Thanks
Alec Kinnear ·
Hi Ryan. Great overview. Any chance you could update this article with any updates to DaVinci Resolve and a detailed overview of the export options with workflow?
Robin Watson ·
From a cursory play around with this feature, you can simply export as an SRT and the text/timecode is all there in readily copy/paste -able form.